
This is the second blog in our series reflecting on findings from a research project conducted earlier this year, involving 15 organisations across the civil service, private sector and charity sector. The project explored how large, complex organisations approach development of data strategies – their ambitions, challenges and practical choices.
Our first blog focused on strategic ambitions. In this post, we turn to the solutions that organisations are using to power their data platforms, and how these compare to DBT’s own approach.
Introduction
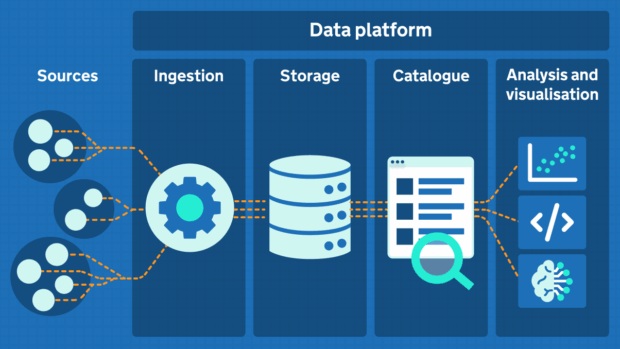
At their core, all data platforms have the same aim – they allow organisations to consolidate different data sets and make them accessible for exploration and analysis.
Yet the way organisations approach this can vary significantly- starting with how the data platform is hosted: on-premises, in the cloud, or through a hybrid model.
Hosting
The discovery revealed that, as mandated, government departments share a common ambition - to fully migrate to the cloud. However, some are still transitioning legacy systems. Among cloud providers, Azure is most commonly used for hosting data platforms, closely followed by Amazon Web Services (AWS).
At DBT we are already using AWS, so it was a natural choice for hosting our data platform, and we are currently migrating the Azure-based CBAS (Cloud-Based Analytical System). Although we don’t actively use Azure, much of our data is stored within Microsoft cloud services like Office 365. Seamlessly integrating this with our AWS-based data platform remains an ongoing challenge.
In contrast, industry participants have largely completed their cloud migration. Many are successful at employing a multi-cloud approach, and some retain on premises infrastructure for high-security or process hungry operations.
Infrastructure
Once the hosting strategy is decided, the next critical consideration is the infrastructure that supports the data platform, particularly around how data will be collected and stored. Most organisations we spoke with rely on proprietary data warehouses and lakehouses such as Snowflake and Databricks. These technologies support distributed architectures and can handle data at the petabyte scale.
At DBT, we’ve taken a different path. We’ve made a deliberate decision to prioritise open source solutions wherever possible. Hence, we built a data platform using PostgreSQL for storage and Airflow for data pipeline orchestration, both open source technologies. These run using AWS services which simplifies maintainability, scalability and reliability while giving us the flexibility to migrate to another cloud provider if needed. Although native Postgres isn’t typically used for analytics, our initial data volumes were modest enough to justify its use. Advances in server performance over recent years have enabled us to handle increasingly large datasets.
Looking ahead, we’re exploring how to make the platform multi-modal supporting a broader range of storage options. This includes investigating how we can better integrate object storage for handling non-tabular and larger scale data sets. We are also evaluating various graph databases for scenarios like supply chain analysis, where graph analytics could offer significant value.
Tooling
After defining the storage architecture, the next logical step is selecting the tooling layer that enable users to interact with and derive insights from the data. Proprietary data platforms often include built-in tools for cataloguing, analysis, and reporting- which can simplify management. At DBT, we are choosing to use a custom-built data platform, which gives us the flexibility to select the tools that best fit our users' needs.
Our data catalogue is tailor-made using Django and the GOV.UK design system- all open source technologies already familiar across DBT services. This helps us meet the GOV.UK service standard and ensures consistency for users. Depending on their use case and skill set, users can choose from open source tools like JupyterLab and RStudio, or proprietary tools like Stata and Amazon QuickSight.
We’ve also recently deployed Amazon Sagemaker to host Large Language Models (LLMs). Our upcoming series of blogs will discuss how we onboard and support users across these tools, including AI and machine learning use cases in more detail.
Tooling access is securely contained and tools can't connect to the internet. Code is managed through a self-hosted GitLab instance, and packages are pulled from internal mirrors. We'll share more on governance and security in a future blog - including how we ensure that users only access the data they’re authorised to see.
Conclusion
While most organisations in our study rely on proprietary platforms hosted on Azure or AWS, we have taken a different route. By building our data platform from the ground up and prioritising open source solutions, we’ve gained greater flexibility and control- tailoring the platform to our users needs. This approach may be less common, but we believe the benefits far outweigh the trade offs. We're committed to open sourcing our platform in the future, so others can build on what we’ve learned and developed.


1 comment
Comment by David H. Deans posted on
The DBT team’s commitment to open source tools, including PostgreSQL, Airflow, Django, and GOV.UK design standards stand out for their emphasis on flexibility, maintainability, and future migration readiness. Indeed, well done.