
Giorgio Di Tunno

Neil Starr

In an earlier post, Andrea Leary highlighted how AI‑ready content can strengthen policy outcomes. Tracey Wilson then showed why clear ownership and active stewardship are critical to keeping content trustworthy. This post explores the practical implementation of those ideas and how we are proactively building a content lifecycle that prevents AI from giving the public incorrect information.
Imagine you want to set up a small charity in your local area. You need to know the costs involved, so you Google ‘how much does it cost to set up a charity UK’.
An AI overview appears. It states in plain English that it costs £40 if you apply by post or £13 if you apply online.
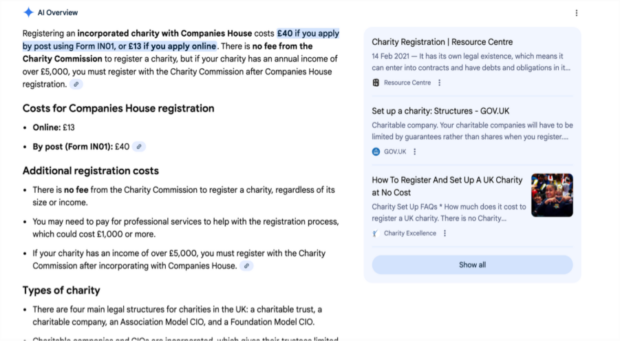
A simple, quick online journey that meets the user’s need.
It would be. If the information were correct.
Since 1 February 2026, the cost to incorporate a company in the UK is £124 if you apply by post or £100 if you apply online - as set out in the Companies House fees guidance.
When it’s time to pay, the user already feels frustrated. Even though the guidance page is correct, the experience still has a negative impact. As one of our user research participants said, “What else does government have out there that is ‘designed to trip you up’?”. The problem isn’t that the government is trying to trip people up (it isn’t), but that inconsistent information surfaced by the AI overview feels that way to users. That perception alone can undermine confidence in government services.
Why AI is picking up incorrect government information
Although the primary page on registering a company was up-to-date, users are increasingly using narrower, more nuanced searches.
This means ‘agentic search’, where GenAI performs multiple steps to meet a user’s objective, looks for content that meets these niche scenarios.
As a result, the GenAI bot pulled information from an unmaintained, unused GOV.UK page that mentioned ‘charity’, instead of the primary GOV.UK page that is regularly monitored.
In the past, most of those outdated, niche pages would fall into the 0-view abyss, never to be stumbled on again. Now, as Andrea outlined in her blog post, GenAI bots are designed to search and gather information from all corners of the internet.
In February 2024, there were 700,000 published pages on GOV.UK. In the 2 years since, that number has increased substantially.
This was never ideal from an environmental perspective. It’s also not what the founders of GOV.UK intended, who wanted nodes of information to help users complete a task, rather than the proliferation of pages.
Not only are GenAI bots picking up outdated information from GOV.UK, but they’re also ‘hallucinating’ answers.
Andrea advocated for AI‑ready content, and Tracey highlighted the importance of clear ownership to maintaining accuracy. This post focuses on the actions we at DBT are taking to address the risks that arise when AI bots meet outdated content.
How we're preventing AI from providing false information
In the content design profession at the Department for Business and Trade (DBT), we’ve committed to a long-running programme of content lifecycle improvements to address these risk of misinformation issues.
Working in partnership with GDS and The National Archives (TNA) we are reshaping how we manage the DBT content estate. We are moving from a one-size-fits-all approach to a policy where we retire content based on a newly developed set of criteria.
Content designers in the Regulations Directorate at DBT have fed into this new approach with valuable insights. They identified 2 methods that we can use to address the issue of AI bots and false government information.
Method 1: auditing and unpublishing outdated content
We kicked this off by performing a manual audit using an existing dataset that enabled us to find all GOV.UK pages that:
- had not been updated in 5 years
- had fewer than 11 views in 5 years
- were a content type that aimed to provide up-to-date information to users (for example, ‘guidance’ or ‘detailed guide’)
- had no owner (were published by a predecessor such as the Department for Business, Energy and Industrial Strategy, and not transferred over to DBT’s estate)
Immediately, we found 150 pages that met all these criteria.
We considered withdrawing them with a banner at the top of the page to state they were out-of-date (example of a withdrawn page), but we’ve seen user research participants just skip over the banner in the past. We also want to guarantee that GenAI bots don’t pick them up.
Therefore, we decided to redirect the pages to either:
- their National Archives alternative (for example, this guidance on regional development agencies)
- a GOV.UK page that better meets their user need
- the new legislation that the old guidance was based on
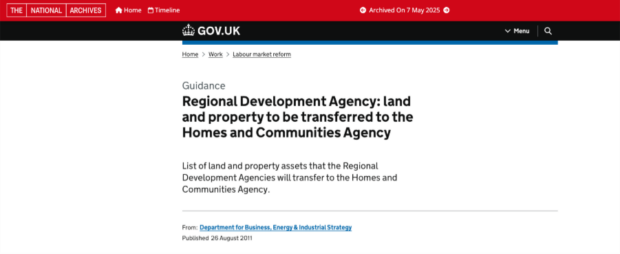
150 pages is a small dent in the growing 700,000-page estate. But it’s a start. And as our tools and methods scale upwards, so will the dent we make.
It’s the beginning of a race with AI, to ensure UK business owners only receive correct information when they search online for guidance to help them comply with regulations.
Method 2: testing a content maintenance plan
To prevent the possibility of future AI hallucinations from content that becomes out of date over time, we have created a semi-automated cross-government content maintenance plan.
We are doing this by building continuous working relationships with the departments and regulators we work with to design specific content. This moves us away from more traditional approaches that treat them as one-off stakeholders.
The plan will ensure these pages are reviewed and updated every 6 months as a minimum.
Whenever a page is updated to reflect changes in regulations, subscribers will be notified, and this grey box pattern will be updated. These tactics match the user needs that were revealed in user research.
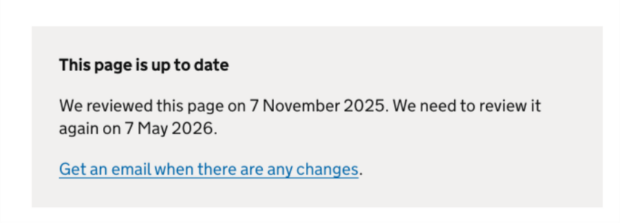
This pattern has tested extremely well with real users. So far, all user research participants have stated that the pattern makes them more likely to use and trust the page.
We are still in the testing phase, and we will continue to update the community as we receive more feedback.
What we're doing next
We are continuing to test and refine our content lifecycle management and retirement policy. There are lots of plans within the department to unpublish more outdated pages and prevent future AI inaccuracies and hallucinations.
We are also working on:
- GOV.UK signposting pages that list all regulations for a specific task, for example rules and regulations for commercial brewing, for sectors with fragmented guidance scattered across multiple departments and regulators
- using the findings from this manual auditing work to create a tool that can automate the hard work of content analysis
We will be publishing a blog post on this work within the coming months.
As mentioned, this is just the beginning.
Earlier, I referred to it as a ‘race’ against AI. But there’s a less combative, more efficient perspective.
It’s an opportunity to reinvigorate government commitment to putting time and resource into well-maintained content lifecycles. This is how we optimise technology to meet users’ needs, such as finding out the cost of setting up a charity in the UK.
How to get involved
Please comment below if you are looking to improve your regulatory guidance or content lifecycles. We look forward to hearing from you.


6 comments
Comment by Angela Moore posted on
Hi Giorgio. This is excellent work. Really interesting to read.
What are you planning around content types such as press releases on GOV.UK? Do you know how these impact AI outputs?
Also, I wondered how you are thinking about measuring the impacts of this work on AI outputs?
Thanks again for sharing the work,
Comment by Giorgio Di Tunno posted on
Hi Angela, I'm glad you enjoyed the post!
On press releases, they're timestamped and tied to a moment, so in theory AI should treat them as historical. In practice though, we've seen GenAI bots pull from press releases when they contain specific figures, particularly if the primary guidance page has been updated since the press release was published. The risk is a press release announcing a policy change gets cited as the current position long after the policy has moved on. The same lifecycle and retirement criteria apply here.
In terms of measuring impacts on AI outputs, we have been comparing signposting topic responses before and after the pages are published. For example, Copilot presented incorrect information about letting out a holiday home before our signposting page was published (that let owners MUST have an EPC rating of E or higher) - now the output is more accurate (that it depends on various factors).
We're purchasing an AI surface tracking toolkit that lets us track how our content appears across AI-generated answers, which pages are being cited, and where inaccurate information is being surfaced. That gives us monitoring at scale rather than manual spot-checks.
We're also looking at referral traffic from AI sources in GA4, tracking sessions from ChatGPT, Perplexity, and Google's AI Overviews. The referral data isn't perfect, but it gives us a directional view of how much traffic is now AI-mediated and whether users are landing on the right pages.
We'll be publishing more blogs in the future to provide updates on this work.
Best wishes,
DBT content and regulations team
Comment by Peter Drake posted on
I agree with Angela’s comment above. In particular I would like to know about the impact of this work on AI outputs
Peter Drake teacher at Queen Elizabeth High School Hexham
Comment by Giorgio Di Tunno posted on
Thanks for your comment, Peter.
We have been comparing signposting topic responses before and after the pages are published. For example, Copilot presented incorrect information about letting out a holiday home before our signposting page was published (that let owners MUST have an EPC rating of E or higher) - now the output is more accurate (that it depends on various factors).
We're purchasing an AI surface tracking toolkit that lets us track how our content appears across AI-generated answers, which pages are being cited, and where inaccurate information is being surfaced. That gives us monitoring at scale rather than manual spot-checks.
We're also looking at referral traffic from AI sources in GA4, tracking sessions from ChatGPT, Perplexity, and Google's AI Overviews. The referral data isn't perfect, but it gives us a directional view of how much traffic is now AI-mediated and whether users are landing on the right pages.
We'll be publishing more blogs in the future to provide updates on this work.
Many thanks,
DBT content and regulations team
Comment by bobsendall posted on
Are the National Archive versions of gov.uk pages excluded for AI bot crawls?
I was just worried that if the TNA pages are crawled by AI the problem of dredging up old content will still exist.
Comment by Chris Brayne posted on
Do you think that https://c2pa.org approaches could be used to provide a "useby date" for content so that AIs could treat accordingly?