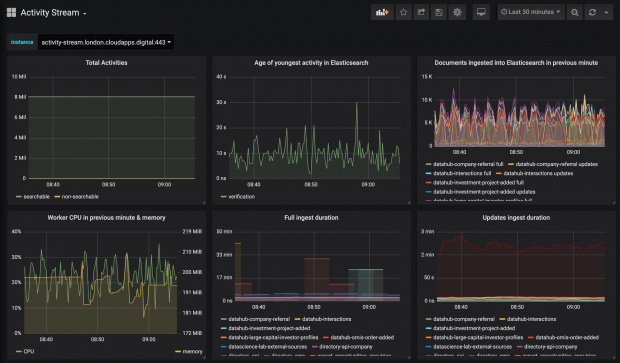
 A screenshot of the Activity Stream dashboard
A screenshot of the Activity Stream dashboard
In the Digital, Data and Technology (DDaT) team, we produce and maintain several web services, both internal and public facing. These services are created by multiple teams with different specialisms, written in a range of programming languages. They need to connect to share data, often in near real time.
We chose to solve this problem by creating an application that sits between the services to carry this data: the Activity Stream.
How the Activity Stream works
Each service that needs to send data to another service exposes a simple Application Programming Interface (API) that the Activity Stream queries. Its pages are ordered chronologically. This allows the Activity Stream to repeatedly ingest all its data by going through all of the pages. It then repeatedly queries the last page to fetch changes.
This is a fairly 'low tech' solution, which means almost any application can do this, but it still has some great properties. For example, our CRM Data Hub, supplies details of hundreds of thousands of interactions that DIT makes with companies. The Activity Stream ingests this data, which is then queried in almost real time by our other services.
Data Format
Every API must supply data in some format. We decided to use the coincidentally named W3C Activity Streams 2.0 as the format for data in the Activity Stream. It is designed for social networks to communicate with each other. The downside of this is that some parts of the Activity Streams 2.0 will likely never be needed, but the benefits of its extendibility outweigh this.
Query language
The Activity Stream stores its data in Elasticsearch, and the language that clients use to query the Activity Stream's data is Elasticsearch's own query language. Some developers may find this unusual, or that it breaks certain rules of API design. This is because many services hide their inner workings and present a different query language to the one used internally.
This choice means that we don’t need to reinvent the wheel. Compared with our own solution, we get a mature query language that is ready to handle many use cases without requiring any code changes. The Elasticsearch query language is also well known which is helpful for hiring developers.
Advantages over a push model
The model of data transfer that the Activity Stream uses is known as a pull model. In a pull model, a client periodically requests data from the source, and the source does nothing unless requested.
The alternative is a push model, where the source sends data to clients, even if they have not asked for it. For the fastest updates, a push model is often chosen. However, a delay of a few seconds is acceptable for our case, which gives us the many advantages of a pull model.
Advantages include:
Single source of truth
Since the Activity Stream repeatedly requests its data from the source, it must be stored there and be its single source of truth. This is important when considering complex systems. If we used a push model, then there’s a risk that data wouldn’t be stored in the source before pushing. Equally it’s very robust, and as soon as it’s saved in the source service, we know it will appear in the Activity Stream, even if the source service went down. This is much harder in push services.
Deletions are handled automatically
In the Activity Stream, the source service deletes data as normal, so the Activity Stream can delete the data the next time it fetches all pages from the source service. This means it’s kept up to date easily. This is especially important with the GDPR Right to be forgotten.
Using existing technology
Rather than investing in anything new we use the Hypertext Transfer Protocol Secure (HTTPS). Our source services already support this, since they're websites. This blog for example, is served to your web browser over HTTPS.
The Activity Stream in action
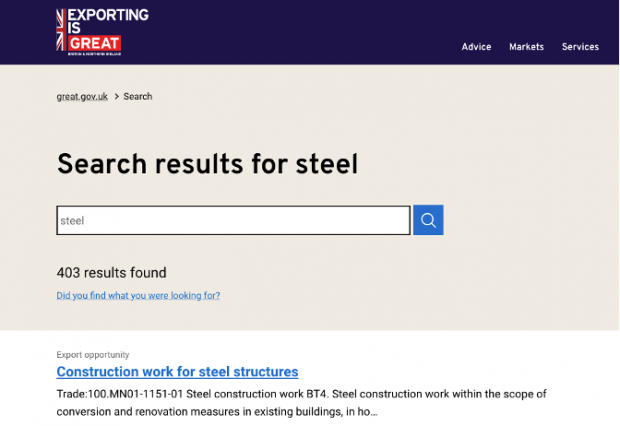 A screenshot of the Activity Steam in action on great.gov.uk
A screenshot of the Activity Steam in action on great.gov.uk
An example of a service that uses the Activity Stream is the search feature on great.gov.uk. It brings together data from several DIT services allowing them to be searched quickly and easily. This allows our developers to build their web services without worrying about the details of robust almost real-time communication with other services in our infrastructure.
As long as they can order data chronologically, which is a very standard ability, and they can expose data via HTTPS, which is what web services do anyway, they can integrate their services with others. Ultimately this means better products for our users.
Enjoyed this blog? Why not extend your reading further and check out more blogs by the technology and data team
Interested in working at DIT? Sign up to receive our job alerts.

